2025 is proving to be the year when AI has finally broken through. Here is an introduction to the topic with no assumption of any background knowledge - well, almost none.
AI and Machine learning
Artificial Intelligence (AI) is a field of computer science which aims to make computers human-level intelligent. This quest is almost as old as digital computers themselves. Alan Turing, regarded as the father of modern computing, famously proposed a test, now called the Turing Test, to judge when computers should be considered intelligent. Imagine you are talking to a panel of entities. However, all conversations are via chat on a screen. You get to chat with each entity in the panel, one at a time. Turing proposed that if some of the entities in the panel were computer programs and some humans, and you couldn't tell just through chatting with those entities, whether one was a program or a human, then that program should be considered intelligent. Turing Test has been the holy grail of AI research.
The field of AI has gone through several rounds of hype cycles and slumps (see AI winter). However, it has persisted and progressed steadily. And we are currently seeing an upsurge in interest.
A major sub-field of AI is Machine Learning. Its aim is to create a computer program that can learn general patterns from data and then act on new data according to what it has learned. i.e. it does not have to be programmed explicitly by a programmer to handle all cases. For example, let us say there is a computer program which has been trained on a set of pictures of Lions, Tigers, Cheetahs & Leopards. After the training is complete, given a fresh picture, the program would recognize whether it is one of these animals.
When the training data, provided to the program is labelled, like in the above example where the training pictures were labelled with the animal's name, is called Supervised learning. Another example is - When you click Report spam on an email, you are effectively training the email system so that it will automatically recognize similar emails as spam in future. Unsupervised learning is when there are no labels attached to the training data, but the program finds patterns in the data. As we will see below, the currently popular LLMs are somewhere in between these two and are called Self-supervised.
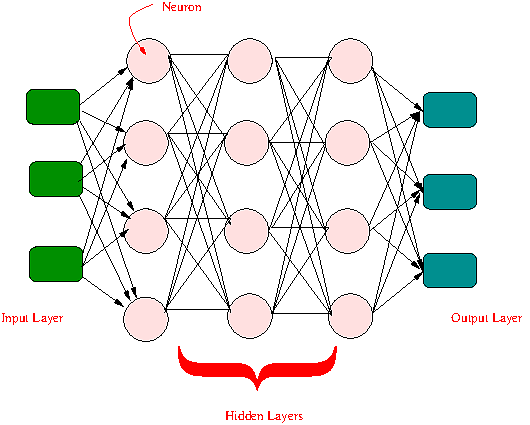
A Neural Network (or Artificial Neural Network) is an architecture commonly used in a machine learning computer program. It is somewhat inspired from a real biological neuron. In AI, a neuron is an entity which take several inputs and produces an output. The output is produced based on a weight that can be adjusted. A neural network has several of these neurons interconnected with each other. Although a single neuron is quite simple, it turns out that a Neural network is a quite powerful learning system which can learn general patterns in unstructured data.
Technically speaking, a single Artificial Neuron is a function of its input. It combines the input is a certain way and that exceeds a threshold, then the output takes a certain value. Importantly, each neuron has a weight that can be adjusted as part of the training. Mathematically speaking, a Neural network is a universal function simulator.
Neural Network
A neural network is called a Deep Neural Network, if it has multiple layers of neurons (the picture above has three layers). Any machine learning program using such a network is then called Deep learning. Modern AI system employ huge neural networks, for instance, ChatGPT has a network of 176B neurons.
When a Neural network is trained on a set of training data, the input is fed to the network and output is observed. If the output is not what is desired, then the weights of neurons in the network are adjusted. There is a very famous algorithm called Backpropagation which is used for adjusting the weights.
LLM
Neural networks have been used in a variety of machine learning programs. However, modern LLM (Large Language Model) systems have used Neural networks to learn language and sentence structure. Here is how that works. Let us say we want to develop a machine learning program, which when given a partial sentence would finish it for you:
Tigers, except when wounded or when man-eaters, are on the whole ___
This problem, called Language modelling, can also be thought of as a classification problem like the cat-family pictures problem described above. Given all the possible words (all the words in a dictionary), the program should pick the most appropriate word to go next.
Tigers, except when wounded or when man-eaters, are on the whole friendly. ❌
Tigers, except when wounded or when man-eaters, are on the whole harmless. ❌
Tigers, except when wounded or when man-eaters, are on the whole good-tempered. ✔️Tigers, except when wounded or when man-eaters, are on the whole lonely. ❌
So how do we train such a program. Turns out that is simple. Let us take a well written sentence. For training, we will hide part of the sentence, and then ask the program to predict the next word. If the prediction is correct, then the program is working well. If it is incorrect, then we will adjust the weights of the neural network. Then again, we ask the program to predict the next word in the sentence, and so on.
Basically, there is no need to label the data, like we needed to label the pictures. Since, the next correct word is already there in the training sentence. We can just hide it to let the program make a prediction. Hence, this scheme is called self-supervised learning.
Once the program has been trained, we can give it a sentence it has never seen before and ask it to predict the next word.
A tiger's function in the scheme of things is to help maintain ___
Let us say, the program predicts:
A tiger's function in the scheme of things is to help maintain the
We then again feed this sentence, with the new word, back into the program and ask it to predict the word after that.
A tiger's function in the scheme of things is to help maintain the balance
We let the program keep going like this till it finishes the whole sentence (see another example in this video). Since, the new sentence is being generated, such a system is often called Generative AI. And that now explains the letter G in GPT, which stands for Generative. P stands for Pre-trained, since it has gone through the self-supervised training on large amounts of text. T stands for Transformer, which is a type of Neural network architecture used. Transformer Architecture, allows it to look at a sequence of words (called Attention) to predict the next word. Transformer Architecture also makes parallel training possible, which makes it faster to train.
As it happens, the modern internet is a treasure trove of texts. All the websites, blogs, social media platforms are just texts, which can be used to train the Neural network based language learning programs. Because of the large size of texts that have used for training, these programs have been called Large Language models (LLM). A model is basically a trained machine learning program.
More on LLMs
As we saw above, LLMs, trained on text, learn sentence structures of natural languages. And such a trained program is called a model. Fine-Tuning and RLHF (reinforcement learning from human feedback) are two techniques which are used to tailor the model for a specific purpose. ChatGPT 3, Claude Sonnet, Gemini 2.5 Pro, Grok 3 etc. are such models. After success with text, modern AI companies realized that they can train a model to work with images, audio and video as well. GPT-4o was one of the first such model (o stands for omni, since it could deal with other formats beside text).
LLMs are trained to predict, not necessarily gargle back, what it saw during the training. That causes a problem. Sometimes, it will just make stuff up which in the real-world would be considered false. This phenomenon is called Hallucination. Note that, LLMs don't really have a concept of truth or falsehood - it's just trying to predict based on the training. As a user, you can reduce hallucinations by providing it as much context as possible. But they are an inherent part of the system. Another common criticism of LLMs is that they cannot have original thought. That also may be a consequence of the fact, at its core, it is a text prediction system.
Another problem LLMs face is that, since the training was done a while ago, it may get out of date. e.g. fast changing news stories or sports updates. AI companies have come up with a solution called RAG (Retrieval Augmented Generation), where fresh current data is retrieved and LLM's results are augmented using that.
LLMs also have to be contained with safety guard-rails so that it does not access or reveal information that should not be exposed to a user. e.g. you should not be able to ask an LLM to give you the number of users currently registered with it or the contact details of all employees within its company. Attempts to get the LLM to violate these boundaries is called AI Jailbreak, and AI companies have to work hard to prevent such a breach.
Conclusion
In this article, we learned about AI and its sub-field machine learning. LLMs are a machine learning system implemented using neural networks. Although LLMs are the breakout star, there are other techniques using which researchers have been trying to build an AI. For an example of an Expert System, see this article.